
Fine-Tuning Large Language Models for Cooperative Tactical Deconfliction of Small Unmanned Aerial Systems
↳ The 3rd Workshop on Multi-Agent Embodied Intelligent Systems Meet Agentic-AI era: Opportunities, Challenges and Futures (MEIS@CVPR 2026)
// abstract
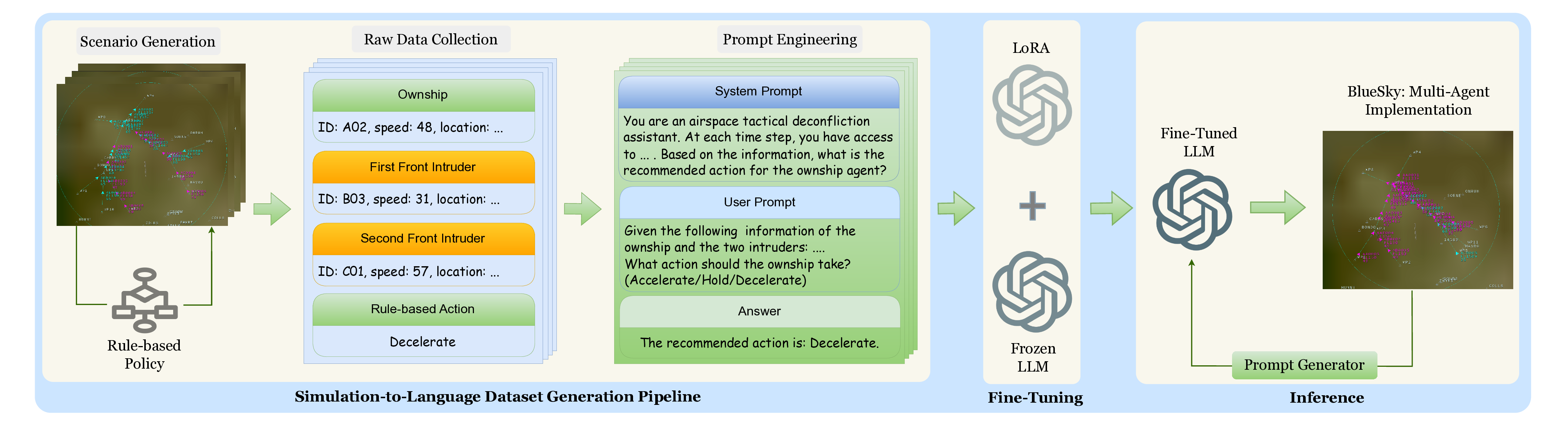
The growing deployment of small Unmanned Aerial Systems (sUASs) in low-altitude airspaces has increased the need for reliable tactical deconfliction under safety-critical constraints. Tactical deconfliction involves short-horizon decision-making in dense, partially observable, and heterogeneous multi-agent environments, where both cooperative separation assurance and operational efficiency must be maintained. While Large Language Models (LLMs) exhibit strong reasoning capabilities, their direct application to air traffic control remains limited by insufficient domain grounding and unpredictable output inconsistency. This paper investigates LLMs as decision-makers in cooperative multi-agent tactical deconfliction using fine-tuning strategies that align model outputs to human operator heuristics. We propose a simulation-to-language data generation pipeline based on the BlueSky air traffic simulator that produces rule-consistent deconfliction datasets reflecting established safety practices. A pretrained Qwen-Math-7B model is fine-tuned using two parameter-efficient strategies: supervised fine-tuning with Low-Rank Adaptation (LoRA) and preference-based fine-tuning combining LoRA with Group-Relative Policy Optimization (GRPO). Experimental results on validation datasets and closed-loop simulations demonstrate that supervised LoRA fine-tuning substantially improves decision accuracy, consistency, and separation performance compared to the pretrained LLM, with significant reductions in near mid-air collisions. GRPO provides additional coordination benefits but exhibits reduced robustness when interacting with heterogeneous agent policies.
// highlights
- A simulation-to-language pipeline built on the BlueSky air-traffic simulator generates rule-consistent deconfliction datasets reflecting established safety practices.
- Fine-tunes a Qwen-Math-7B model with two parameter-efficient strategies: supervised LoRA and preference-based LoRA + GRPO.
- Supervised LoRA substantially improves decision accuracy, consistency, and separation, with significant reductions in near mid-air collisions.
- GRPO adds coordination benefits but is less robust when interacting with heterogeneous agent policies.
// notes
This paper presents a simulation-to-language data generation pipeline using BlueSky ATM for fine-tuning Large Language Models on cooperative tactical deconfliction of small UAS, achieving improved decision accuracy and reduced near mid-air collisions through parameter-efficient fine-tuning (LoRA, GRPO).
This manuscript is published at MEIS CVPR 2026 Workshop.
// bibtex
@inproceedings{sharifi2026finetuning,
title = {Fine-Tuning Large Language Models for Cooperative Tactical
Deconfliction of Small Unmanned Aerial Systems},
author = {Iman Sharifi and Alex Zongo and Peng Wei},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages. = {1067--1076},
year = {2026},
note = {MEIS @ CVPR 2026 Workshop}
}// cite
Sharifi, I., Zongo, A., & Wei, P. (2026). " Fine-Tuning Large Language Models for Cooperative Tactical Deconfliction of Small Unmanned Aerial Systems. " In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1067-1076).